Inderator User Manual:
By Cluedapp (Pty) Ltd
Version 1.0.7
26 April 2020
Inderator stands for Website Index File Generator. As the name implies, it is a utility program to generate static index files for websites.
Inderator is written in C#. .NET Framework 4.7.2 or Mono Project is required to run Inderator.
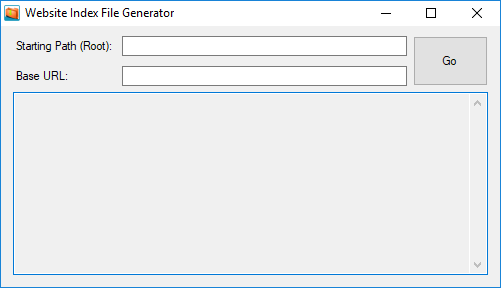
Inderator walks a directory tree, given by a root folder that you specify in the program, and generates an index.html file in every non-empty folder. The root folder itself is not indexed.
Each index.html file is generated based on a “master” template file in the root folder. A “master” header and a “master” content file can be placed in each sub-folder, which will be included in the final index.html file, which is written to each folder. In case the current folder does not have a header and/or a content file, then the header and content files from the root folder are used.
Inderator can also be configured to ignore certain filenames, so that they will not be included inside the listings of the generated index.html files.
index.html files are not generated in empty folders. An empty folder is a folder that does not contain any listable files, either because all the ignored files in it have been filtered out, or because it does not contain any files or sub-folders on the file system. However, empty folders are still listed in their parent folders, but no anchor link is generated in the parent folder’s listing, to enter the empty folder, and neither is an index.html generated in the empty folder, as previously stated.
Inderator’s settings file uses a nice and simple JSON configuration format. The name of the settings file is hardcoded as inderator.json, and the file should be placed in the same loaction as inderator.exe. An example of inderator.json:
{
"rootFolder": "c:\\path\\to\\root\\folder",
"baseURL": "http://example.com/",
"ignoreFiles": ["index.htm", "index.html", "_header.html", "_content.html", "desktop.ini"]
}
Description of configuration settings:
- rootFolder: path to the root folder to be indexed
- baseURL: the base URL to use for generated listings
- ignoreFiles: an array of filenames to ignore as part of the generated listing in index.html
When you run the program and start the indexing process, the path to the root folder, as well as the specified Base URL for the website, is saved to inderator.json in the same directory as inderator.exe, and these settings are loaded back in, when Inderator is started again at a later time.
Template engine:
Inderator uses a basic template engine to generate index.html files.
A single master index template file is used by the engine, and its name is hardcoded as _template.html. This file must be located in the root folder that is being indexed.
Inside _template.html, you can place four placeholder sections, which will automatically be substituted with the appropriate generated information, for the current folder being indexed. This process generates and writes an index.html file for each folder that is indexed.
The placeholder sections are:
- [HEADER]
- The content of _header.html in the root folder or in the current folder, is substituted into this placeholder in the final index.html file
- [CONTENT]
- The content of _content.html in the root folder or in the current folder, is substituted into this placeholder in the final index.html file
- [NAVIGATION]
- A breadcrumb trail to the current folder being indexed is generated, by splitting the path of the current folder into portions divided by the \ character, and writing each portion as a navigation link. For example,
- Root folder: C:\My Websites\cluedapp.co.za\Webroot
- Sub-folder: C:\My Websites\cluedapp.co.za\Webroot\Projects\Test Project\Source
- Navigation generated:
<li><a href="/Projects/">Projects</a></li><li><a href="/Projects/Test%20Project/">Test Project</a></li><li><a href="/Projects/Test%20Project/Source/">Source</a></li>
- A breadcrumb trail to the current folder being indexed is generated, by splitting the path of the current folder into portions divided by the \ character, and writing each portion as a navigation link. For example,
- [LINK]
- A listing of the files and folders in the current folder being indexed. An example listing:
<li class="folder empty">Empty folder</li><li class="folder"><a href="Non-empty%20folder/">Non-empty folder</a></li><li class="folder compressed"><a href="Folder.zip">Folder</a></li><li class="folder compressed"><a href="Folder.rar">Folder</a></li><li class="file"><a href="file.txt">file.txt</a></li>
- A listing of the files and folders in the current folder being indexed. An example listing:
Compressed files:
If a .zip or .rar compressed file is found in a folder, and the compressed file has the same name as a sub-folder within the folder, then the compressed file is listed appropriately, and a <meta> tag is added to the <head> tag in the [HEADER] template (or just appended to the [HEADER] template if no <head> tag is present), for that subfolder’s generated index.html file. For example:
- C:\My Websites\cluedapp.co.za\Webroot\Projects\Test Project\Folder.zip is found, and the folder C:\My Websites\cluedapp.co.za\Webroot\Projects\Test Project\Folder\ exists.
- Add <li class=”folder”><a href=”Folder/”>Folder</a></li><li class=”folder compressed”><a href=”Folder.zip”>Folder.zip</a></li> to the [LINK] template for the index.html file in the folder that contains Folder.zip and the Folder sub-folder.
- Add <meta name=”download” content=”{BaseURL}/Projects/Test%20Project/Folder.zip” /> to the [HEADER] template for the index.html file in the Folder sub-folder, where {BaseURL} is the Base URL configured on the Inderator user interface.
A similar process is performed if Folder.rar was found instead of Folder.zip.
Links:
https://www.cluedapp.co.za/inderator